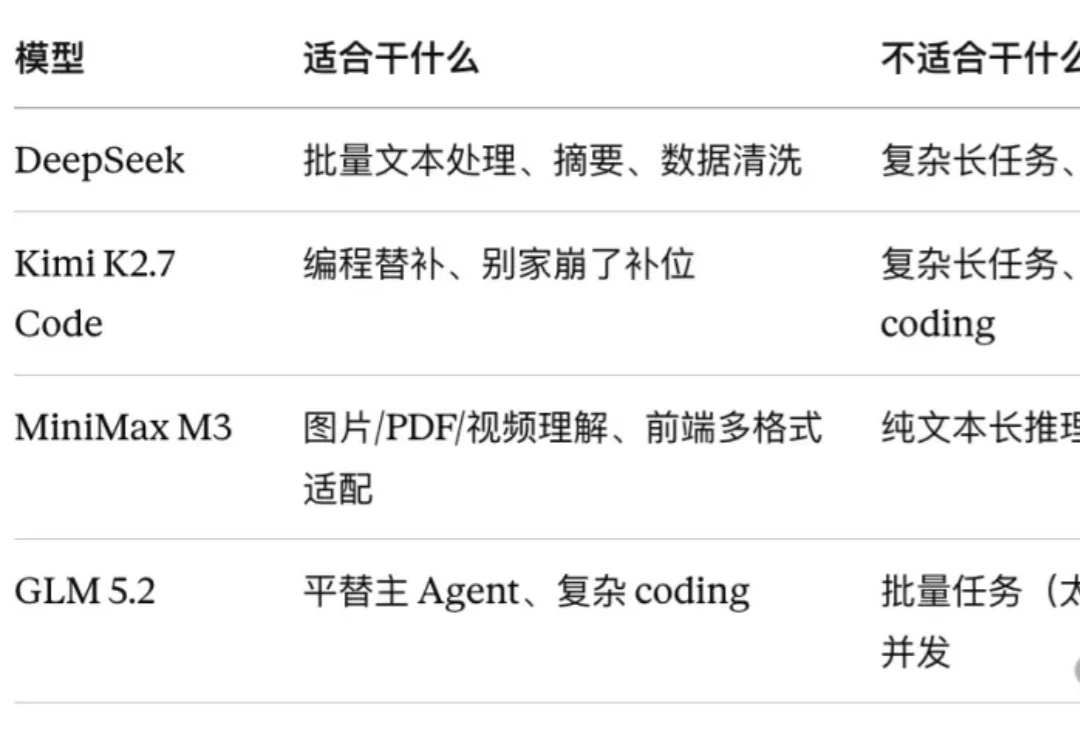
GLM5.2、Kimi2.7、DeepSeek V4、MiniMax M3最佳搭配清单,你可以直接抄
GLM5.2、Kimi2.7、DeepSeek V4、MiniMax M3最佳搭配清单,你可以直接抄最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
来自主题: AI资讯
10246 点击 2026-06-18 10:15
 搜索
搜索
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
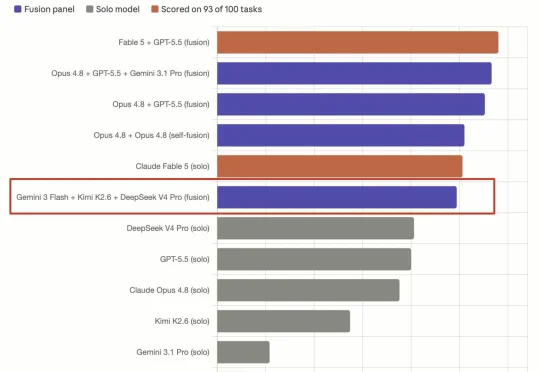
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

“AI新物种”企业级Token生产平台TokenBox™。
Hunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
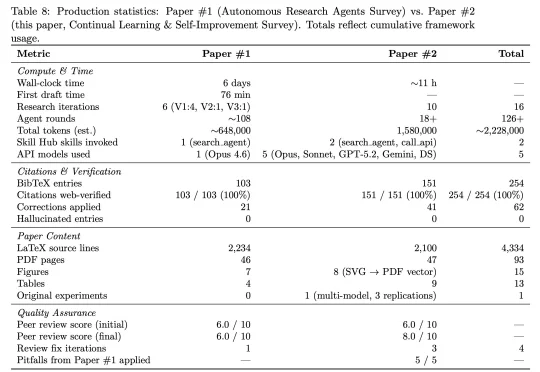
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

最近,DeepSeek又刷屏了!